
The Rise of Small Language Models: Why 2026 Marks the Shift Away from One-Size-Fits-All AI
By Jannat Azam • March 4, 2026
Let's talkContent
For the last few years, most AI systems have been built around Large Language Models (LLMs). GPT, Claude, and Gemini became default components across products, teams, and domains.
New ideas often start the same way: integrate one of these models and see how far it gets. That approach worked longer than expected.
Small Language Models (SLMs) existed alongside this shift, mostly out of focus. Narrow models, trained or tuned for a specific task, with explicit limits on what they were expected to do.
As systems mature heading into 2026, those narrower models are no longer peripheral. They are increasingly where real design decisions are being made.
Failure Surfaces with General-Purpose Models in Production
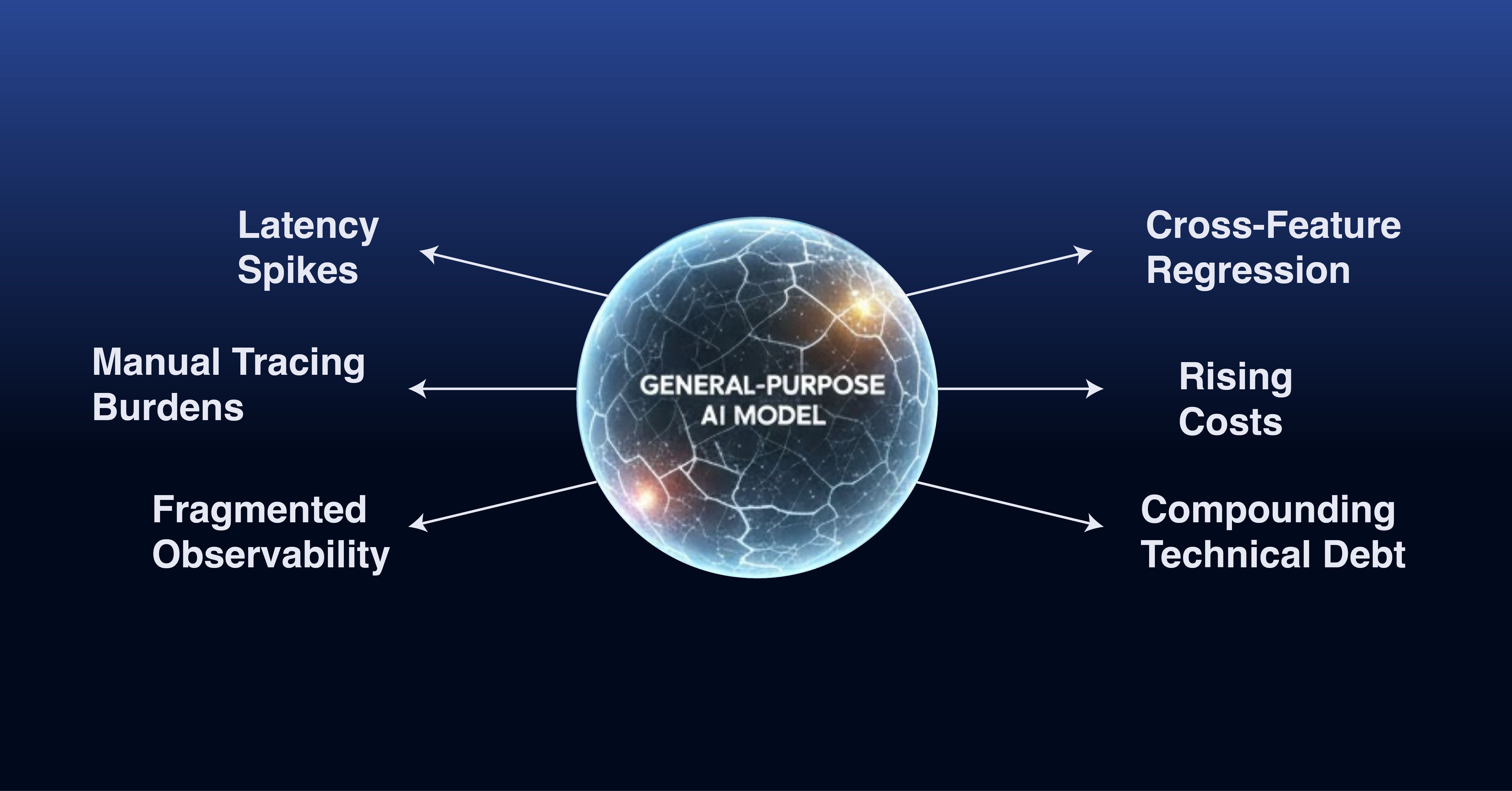
Once a large language model transitions from prototype to production, the challenges shift from benchmarks to predictability, visibility, and system impact.
Latency Variability
While average latency may seem acceptable, P95/P99 latency spikes become an issue under load. Minor changes in input length, prompt structure, or traffic volume can cause unpredictable delays. These spikes spread through the system, affecting downstream components and creating inconsistent response times.
Cost Attribution
General-purpose models usually have multiple features, each with varying usage patterns. As these models evolve, tracking token usage becomes increasingly difficult. Even small prompt changes can increase the costs that are difficult to explain. When multiple teams share a model, figuring out which feature is driving cost often requires manual work.
Feature Interactions
A single model supporting multiple features leads to unexpected interactions. A change made for one feature can affect others in ways that are not immediately visible, introducing bugs or performance degradation. Managing model versions becomes a coordination task, with multiple teams that need to align on updates and check for side effects.
Observability Challenges
Failures often show up downstream, far from the original model call. Logs and metrics usually provide only partial information. Tracking issues back to the source often requires manual investigation, which slows debugging and makes root cause analysis harder. These issues rarely block a system right away. They build up over time and add friction to daily operations. Teams often respond by adding more checks and patches around the model, which increases system complexity and reduces clarity.
How 2026 Marks the Shift Away from All-in-One AI Models
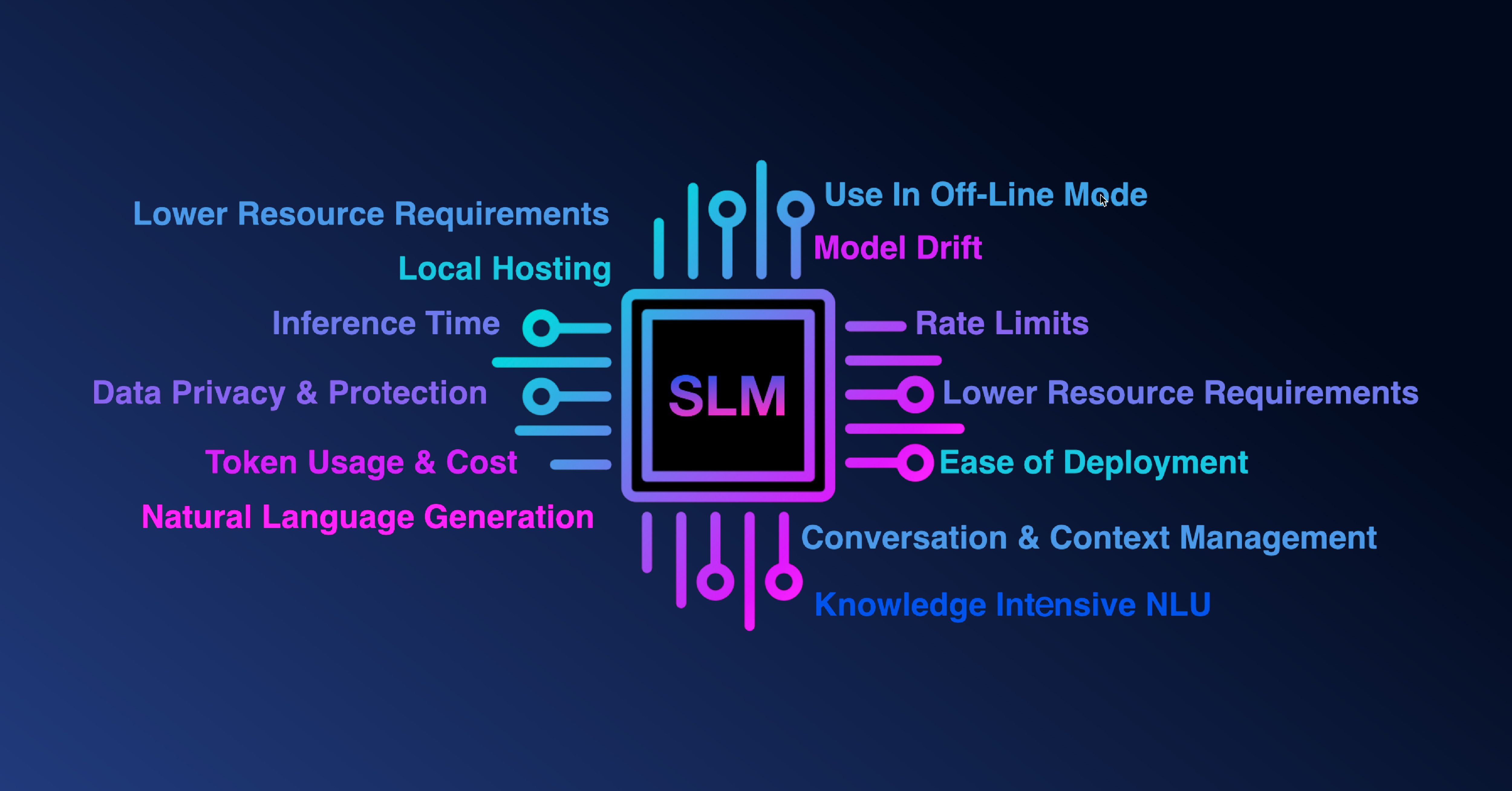
The rise of Small Language Models (SLMs) in 2026 is driven by the operational friction of using large, general-purpose models in production environments. While general-purpose models are useful for discovery, they often fail the stress tests of reliability and financial sustainability when applied to specific business logic. We are seeing a move toward models that do one thing reliably rather than many things unpredictably.
Reliability in the Logic Path
Predictability is the most important metric for any engineer managing a production system. General-purpose models often introduce latency spikes that are difficult to diagnose. As these models are massive, their response times can fluctuate based on cluster load or the complexity of the internal reasoning path. SLMs provide a different experience. When a model is designed for a narrow task, such as classifying a support ticket or extracting data from a specific form, the compute requirements are fixed. The model follows a shorter path to the answer. This consistency leads to stable P99 response times. It allows us to build interfaces that feel fast and responsive to the end user.
Unit Economics and Resource Use
As AI moves from experimental budgets to core P&L considerations, it’s no longer justifiable to run a general-purpose model for specific tasks like sentiment analysis. SLMs allow for tight control over unit economics, consuming fewer resources (memory, GPU cycles) while maintaining predictable costs. By optimizing for the task at hand, teams can allocate resources more effectively and prioritize features that deliver true value.
Decoupling and System Maintenance
The monolithic approach to AI makes versioning a high-risk activity. When you update a single large model used across ten different features, you risk breaking logic in parts of the application you were not even testing. Using SLMs changes this dynamic. Each model functions like a microservice. If the team needs to update the logic for a specific data extraction tool, they can update that specific SLM without touching the rest of the stack. This modularity reduces the scope of regression testing. It makes the system easier to maintain because the code and the model are tightly coupled to a single responsibility.
Faster Debugging and Error Attribution
Observability is a challenge with general-purpose models because the "why" behind a failure is often buried in a massive latent space. If a model starts giving wrong answers, it can be hard to tell if the issue is the prompt, the model version, or a change in the underlying training data.
With SLMs, the task is bounded. If a model designed for medical coding starts making errors, we can quickly isolate the failure to its specific domain. The logs are cleaner, and the performance metrics are tied to a defined outcome. This clarity speeds up the debugging process. Engineers spend less time guessing why a model behaved strangely and more time fixing the specific data points that caused the issue. Architecting for Local and Edge Compute
As AI systems evolve in 2026, the demand for privacy and low-latency processing is pushing models closer to the user. SLMs, with their compact size, can run efficiently on local servers or even on edge devices. This shift not only ensures better privacy by keeping data within the user’s environment but also reduces network dependency, improving resilience in less stable environments.
Conclusion:
2026 marks the turning point in AI architecture. The limitations of general-purpose models in production environments are becoming clear, making way for Small Language Models (SLMs). With their focus on predictability, cost-efficiency, and scalability, SLMs offer a better fit for modern AI systems.
As businesses demand more control and consistency, SLMs are quickly replacing general-purpose models for specialized tasks. This shift signals a future where narrow, task-specific solutions are the norm, optimizing performance and resource use in a way general models never could.